| ▸ Tablouri bidimensionale (matrice) | | Tablouri bidimensionale (matrice)
Tablouri
bidimensionale – matrice
Un tablou cu două dimensiuni se numeşte matrice.
Declarare
int
a[50][100], n, m, i, j;
S-a declarat:
– o matrice cu maxim 50 de linii şi 100 de coloane, numerotarea se face de la 0 sau de la 1.
– n- numarul efectiv de linii;
– m-numarul efectiv de coloane;
– i- contor pentru linie
– j- contor pentru coloane
Citire:
for(i=1; i<=n;i++)
for(j=1;j<=m;j++)
{
cout<<”a[“<<i<<”][“<<j<<”]=”;
cin>>a[i][j];
}
Afisare:
for(i=1;i<=n;i++)
{
for(j=1;j<=j;j++)
cout<<a[i][j]<<”
“;
cout<<“
”;
} Matrice
patratica Într-o
matrice pătratică numarul de linii= numarul de coloane (n=m). Într-o
matrice pătratică avem:
-
Diagonala
principala elementele a[i][i], cu i=1,n sau a[i][i], cu i=0,n-1
-
Diagonala
secundara elementele a[i][n-i+1], i=1,n sau a[i][n-i-1], i=0,n-1
Zonele determinate de diagonale:
I.
Pe diagonala principală i=j
Sub diagonala principala: i>j
Deasupra diagonalei principale: i<j
II.
Pe diagonala secundară j=n-i+1
Sub diagonala secundara: j>n-i+1
Deasupra diagonalei secundare:j<n-i+1
|  |
| | ▸ Siruri de caractere (citire, tiparire) | | Siruri de caractere (citire, tiparire)
ȘIRURI DE CARACTERE Limbajul
C/C++
permite initializarea unui tablou de caractere printr-o constanta sir,
care
include automat
caracterul
NULL
Caracterul NULL '\0' se adauga atutomat
dupa ultimul caracter
din sir.
'\n' - caracterul linie noua deci cout<<endl; chivalent cu cout<<'\n';
Exemplu :
char vect[11]=”calculator”;
char vect[]=”calculator”; (compilatorul face calculul
numarului de
octeti necesari)
char vect[100]=”calculator”; (s-au rezervat mai
multi octeti
decat era necesar)
1
Sirurile de caractere sunt de fapt tablouri de caractere, care au ca ultim element un terminator de sir, caracterul NULL. Exemplu:
char tc[5] = {’a’, ’b’,
’c’, ’d’, ’e’}; //
tablou de caractere
char sc[5] = {’a’, ’b’,
’c’, ’d’, ’\0’}; //
sir de caractere cu elementele abcd
Ultima initializare este echivalenta cu:
char sc[5] =
”abcd”; //sau char sc[] =
”abcd”; char sc1[5]
= ”abcd”;
char s[10];
cout<<sc<<endln; //afiseaza abcd
cout<<tc<<endl; //eroare:
tabloul
de caractere nu
contine terminatorul de sir, deci
nu poate fi afisat
ca sir
cout<<s<<endl;
//
eroare: tablou neinitializat
cout<<sc1[0]; // afiseaza primul caracter din sirul sc1
cout<<sc1[2]; /
/ afiseaza al treilea element din sirul sc1
sc1[1]=’K’; // elementului din sir de indice 1 i
se atribuie valoarea
„K‟;
CITIREA / AFISAREA SIRURILOR DE
CARACTERE
Sirurile
de caractere
pot
fi initializate inca de
la
declarare sau citite pe
parcursul programului.
a.
Citirea
unui
sir de caractere se
poate
face ca citirea oricarui tablou,
intr-un for,
caracter cu
caracter
(desi nu este
recomandata). In acest
caz, terminatorul
de sir
nu este memorat automat,
el trebuie pus
explicit dupa ultimul caracter din sir.
Exemplu:
char c[20];
for(int i=0;i<=5;i++)
cin>>c[i];
cout<<c<<endl; //se va afisa sirul
format din cele 6 caractere,
urmat de caractere „reziduale”,
//initializate
implicit la compilare, din cauza
ca n-a fost pus terminatorul de sir
c[6]='\0';
cout<<c<<endl; //a fost pus terminatorul
de sir, deci sirul va fi afisat corect
b. Se poate face pur si
simplu, folosind cin>>.
Caracterul nul este adaugat automat.
Dezavantajul
este ca in acest
fel
nu se pot citi siruri care
contin
mai multe cuvinte separate prin
spatii. Citirea sirului se sfarseste la intalnirea
primului
caracter
blank (de ex,
daca se citeste
“ora de informatica”,
variabila c va retine numai “ora”).
Exemplu char c[30]; cin>>c;
cout<<c;
c.
Se poate
folosi o functie speciala pentru citirea
sirurilor de caractere,
inclusa in biblioteca string.h (varianta recomandata).
Exemplu char a[30],x;int nr; cin.get(a,nr,x
); Functia cin.get
citeste un sir de caractere sau pana cand au
fost citite
nr-1 caractere, sau
daca s-a intalnit
caracterul x. Al
treilea
parametru poate lipsi,
caz in care el este
implicit caracterul ‟\n‟ (new line). Sunt citite si caracterele albe, caracterul NULL este inserat automat iar
caracterul
transmis ca ultim parametru nu este inserat in sir. E
xemplu char a[30];
cin.get(a,5,’s’); //daca se citeste
sirul “maimuta,
variabila a
va retine
“maim” cin.get(a,15,’s’); //daca se citeste
sirul “maimuta,
variabila a
va retine
“maimuta” cin.get(a,15,’t’); //daca se citeste
sirul “maimuta,
variabila a va
retine “maimu” 2
cin.get(a,4,’t’); //daca se
citeste sirul “maimuta, variabila
a va
retine “mai” cin.get(a,10); //daca se citeste
sirul “maimuta,
variabila a
va retine
“maimuta”
Functia cin.get( ) fara parametri are rolul de a citi un caracter
(alb sau nu).
Observatie
: In cazul utilizarii repetate a functiei
cin.get(a,nr,x), dupa fiecare folosire trebuie citit caracterul de la
sfarsitul fiecarui
sir , adica ‟\n‟ (in
caz contrar,
acest caracter va
fi incarcat
la inceputul urmatorului sir, a carui citire se
termina la caracterul Enter, deci citirea celui de-al doilea sir se termina inainte
de a incepe, iar al
doilea sir va
fi sirul vid).
Aceasta citire a
caracterului ‟\n‟ se realizeaza folosind cin.get() fara parametri. Exemplu
char a[30],b[30]; cin.get(a,15);
cin.get(b,10); Daca se
incearca citirea
sirurilor „sarbatoare” si
„vacanta”,
se observa ca
a=”sarbatoare”, b=”” (nici nu apucam sa citim sirul b). Varianta corecta
este: cin.get(a,15); cin.get();
cin.get(b,10); Afisarea unui sir de
caractere
se face folosind
cout.
cout<<a; Se poate afisa
si caracter cu caracter, ca in
cazul tablourilor, dar aceasta varianta nu este
recomandata. | |
| | ▸ FUNCTII PENTRU OPERATII CU SIRURI DE CARACTERE | | FUNCTII PENTRU OPERATII CU SIRURI DE CARACTERE
Functiile
pentru
operatii cu siruri se gasesc in
header-ul
.
Ø Functia strlen
int strlen
(nume_sir); – returneaza
lungimea efectiva a unui sir
(fara
a numara
terminatorul
de
sir).
Ex
emplu:
char a[50]=”ora de informatica”; =>
strlen(a) = 18
Ø
Functia strcpy
strcpy(sir_destinatie,sir_sursa); – copiaza sirul sir_ sursa
in sir_destinatie (se
simuleaza
atribuirea a=b)
.
ATENTIE!! Nu este permisa
atribuirea intre
doua siruri
de caractere folosind operatorul =
. Atribuirea se face folosind functia strcpy
.
Exemplu:
char
a[50]=”primul sir”,b[40]=”al doilea sir”;
a=b;
//eroare
strcpy(a,b); =>
a = ”al doilea
sir”; b=”al doilea
sir”;
Ø Functia
strcat
strcat(dest,sursa); –
adau
ga sirului dest sirul sursa. Sirul sursa ramane nemodificat.
Operatia
se
numeste concatenare si
nu este comutativa.
Exemplu:
char
*a=”vine ”,*b=”vacanta?”; strcat(a,b);
=> a = ”vine vacanta?”;
Ø Functia strncat
strncat(dest,sursa,nr);
– adauga
dest primele nr caractere din sirul sursa.
Sirul sursa ramane
1
nemodificat.
E
xem
plu:
char *a=”vine ”,*b=”vacanta?”; strncat(a,b,4); => a =
”vine
vaca”;
Ø Functia
strchr
strchr(sir,c); –
are rolul de
a cauta caracterul c in sirul
sir. Cautarea se face
de la stanga la dreapta, iar functia intoarce adresa
subsirului care incepe cu
prima aparitie
a caracterului c. Daca nu este
gasit caracterul, functia returneaza 0. Diferenta dintre
adresa sirului initial si cea a subsirului returnat reprezinta
chiar pozitia caracterului cautat in
sirul dat.
Exemplu:
char *a=”acesta este un
sir”, b=’t’, c=’x’, *d;
cout<
=> se tipareste
”ta este un sir”;
cout< => nu se
tipareste
nimic (se tipareste
0 daca
se face
o conversie la
int a lui
strchr(a,c)
;
d=
strchr(a,b);
cout<<”Caracterul
apare prima data
la pozitia
”<a;
Ex: Sa se afiseze
toate pozitiile unui
caracter intr-un
sir
#include
#include using namespace std;
int main()
{char a[100],*p,c;
cin.get(a,100); cin>>c; p=strchr(a,c);
while (p)
{cout<<"Pozitia "<
p=strchr(p,c);}
return 0;}
Ø Functia strrchr
strrchr(sir,c);
– are acelasi rol cu
strchr, cu deosebirea ca
returnea
za adresa ultimei aparitii a caracterului
(cautarea se face de la dreapta
spre
stanga; r = right)
Ø Functia st
rcmp
int
strcmp(sir1,sir2); –
are rolul
de a compara doua siruri de caract
ere. Valoarea
returnata este <0 (daca sir1<
sir2), =0 (daca sir1=sir2) si >0 (daca sir1>sir2). Functia strcmp
face distinctie
intre literele
mari si cele mici
ale alfabetului.
Obs
: Functia
strcmp returneaza diferenta dintre codurile ASC
II ale primelor
caractere care
nu coincid int stricmp(sir1,sir2); – are acelasi rol cu strcmp, cu deosebirea ca nu face distinctie intre literele
mari si cele
mici ale
alfabetului (i = ignore).
Functia strstr
strstr(sir1,sir2); – are rolul de a identifica daca sirul sir2 este subsir al sirului sir1. Daca este, functia returneaza adresa
de inceput
a subsirului sir2
in sirul sir1, altfel returneaza adresa 0. In cazul in care sir2 apare de mai multe ori in sir1, se returneaza adresa de inceput a primei aparitii.
Cautarea se face
de la stanga la dreapta
Functia strtok
- strtok(sir1,sir2); – are rolul de a separa sirul sir1 in mai multe siruri (cuvinte) separate intre ele prin unul sau mai multe
caractere
cu rol de separa
Sirul sir2 este alcatuit din unul sau mai multe caractere
cu rol de separator.
Functia strtok actioneaza in felul urmator:
o Primul apel trebuie sa fie de forma strtok(sir1,sir2); Functia intoarce adresa primului caracter al primei entitati. Dupa
prima
entitate, separatorul este
inlocuit automat prin caracterul nul.
o Urmatoarele apeluri sunt de forma strtok(NULL,sir2); De fiecare data, functia intoarce adresa de inceput a
urmatoarei entitati,
adaugand automat dupa
ea caracterul nul.
o Cand sirul nu mai contine entitati, functia returneaza adresa nula.
Exemplu:
//Sa se separe cuvintele dintr-un text.
#include <iostream.h>
#include <string.h>
int main()
{char text[100],cuv[10][10],*p,*r,separator[]=",. !?";int i=0,nr=0; clrscr();
cout<<"Dati sirul:";cin.get(text,100); strcpy(p,text); p=strtok(p,separator);
while (p)
{strcpy(cuv[++nr],p); p=strtok(NULL,separator);}
cout<<"Sunt "<<nr<<" cuvinte:"<<endl; for (i=1;i<=nr;i++) cout<<cuv[i]<<endl; return 0;}
- Functia strspn cu forma generala
int strspn(sir1,sir2); – are rolul de a returna numarul de caractere ale sirului sir1 (caractere consecutive care incep
obligatoriu cu
primul caracter)
care se gasesc in sirul sir2.
Exemplu:
strspn(“AB2def”,”1B3AQW”); à returneaza 2, pentru ca primele 2 caractere „A‟ si „B‟ din sir1 se
gasesc in sir2.
strspn(“FAB2def”,”16A32BF”); à returneaza 0, deoarece caracterul „F‟ cu care incepe sir1 nu se gaseste in
sir2.
Functia strcspn
cu forma generala
int strspn(sir1,sir2); – are rolul de a returna numarul de caractere ale sirului sir1 (caractere consecutive care incep
obligatoriu cu
primul caracter)
care nu se gasesc in sirul sir2.
Exemplu:
strspn(“AB2def”,”123”); à returneaza 2, pentru ca primele 2 caractere din sir1 nu se gasesc in
sir2.
//Se citeste un sir de caractere care nu contine caractere albe. Sa se decida daca sirul este alcatuit exclusiv din
caractere
numerice.
#include <iostream>
#include <string.h> using namespace std; int main()
{char text[100],cifre[]="0123456789"; cout<<"Dati sirul:";cin.get(text,100);
- if (strcspn(cifre,text)==strlen(text)) cout<<"exclusiv numeric";
else
cout<<”nenumeric”;
return 0;}
- Functia strlwr cu forma generala
strlwr(sir); – are rolul de a converti toate literele mari din sir in litere mici. Restul caracterelor raman neschimbate.
- Functia strupr cu forma generala
strupr(sir); – are rolul de a converti toate literele mici din sir in litere mari. Restul caracterelor raman neschimbate
Functia strbrk
cu forma generala
strpbrk(sir1,sir2); – actioneaza in felul urmator:
o Cauta primul caracter al sirului sir1 in sir2. Daca este gasit, returneaza adresa sa din cadrul sirului sir1 si executia
se termina.
Altfel, se trece la pasul
urmator.
o Cauta al doilea caracter al sirului sir1 in sir2. Daca este gasit, returneaza adresa sa din cadrul sirului sir1 si executia
se
termina. Altfel, se trece la pasul
urmator.
o …
o Daca nici un caracter al sirului sir1 nu apartine sirului sir2, functia returneaza adresa nula.
Functia atof cu forma generala
double atof(sir); – converteste un sir catre tipul double. Daca aceasta conversie esueaza (se intalneste un caracter
nenumeric),
valoarea intoarsa
este 0. Aceasta functie (ca si cele similare) necesita includerea librariei stdlib.h.
Functia atoi
cu forma generala
int atoi(sir); – converteste un sir catre tipul int. Daca aceasta conversie esueaza (se intalneste un caracter
nenumeric), valoarea
intoarsa este 0.
Functia atol
cu forma generala
long atol(sir); – converteste un sir catre tipul long. Daca aceasta conversie esueaza (se intalneste un caracter
nenumeric),
valoarea intoarsa este 0.
Functia itoa
cu forma generala
itoa(int valoare,sir,int baza); – converteste o valoare de tip int in sir, care este memorat in variabila sir. Baza retine
baza de
numeratie catre care sa
se faca conversia. In cazul bazei 10, sirul retine si eventualul semn -.
- Functia ltoa cu forma generala
ltoa(long valoare,sir,int baza); – converteste o valoare de tip long int in sir, care este memorat in variabila sir.
- Functia ultoa cu forma generala
ultoa(unsigned long valoare,sir,int baza); – converteste o valoare de tip unsigned long in sir, care este memorat in variabila sir. | |
| | ▸ SUBPROGRAME | | SUBPROGRAMESubprogramele sunt părţi ale unui program,
identificabile prin nume, care se pot activa
(apela) la cerere prin intermediul acestor nume.
Prezenţa subprogramelor implică funcţionarea în strânsă legătură a
două noţiuni: definiţia unui subprogram şi apelul unui
subprogram.
Definiţia unui subprogram reprezintă
de fapt descrierea unui proces de calcul cu ajutorul variabilelor virtuale (parametri formali) iar apelul unui
subprogram nu este altceva decât execuţia procesului de calcul pentru cazuri concrete
(cu ajutorul parametrilor reali,
(efectivi, actuali) ).
Structura
unui subprogram C++
Un
subprogram (funcţie) are o definiţie şi atâtea apeluri câte
sunt necesare.
Definiţia
unei funcţii are forma generală:
tip_returnat
nume_funcţie (lista parametrilor formali)
{
instrucţiune; //
corpul funcţiei
return
valoare;
}
|
Tip_returnat
|
Reprezintă
tipul rezultatului calculat şi returnat de funcţie şi poate fi: int, char,
char*, long, float, void, etc.
În
cazul în care tipul rezultatului este diferit de void, corpul funcţiei
trebuie să conţină cel puţin o instrucţiune return. Înstrucţiunea
return va specifica valoarea calculată şi returnată de funcţie care trebuie
să fie de acelaşi tip ca şi tip_returnat.
|
|
Nume_funcţie
|
Reprezintă
numele dat funcţiei de către cel ce o defineşte, pentru a o putea apela.
|
|
Lista_parametrilor_formali
|
Reprezintă
o listă de declaraţii de variabile separate prin virgulă. Această listă poate
să fie şi vidă.
|
|
Instrucţiune
|
Este
o instrucţiune vidă sau o instrucţiune simplă sau o instrucţiune compusă.
|
Există două tipuri de
subprograme:
ü De
tip funcție – returnează o valoare
ü De
tip procedură (void) - nu returnează
direct o valoare, dar poate returna prin intermediul parametrilor săi.
În cazul
subprogramului de tip procedură Tip_returnat este
void, instrucțiunea return nu apare. Apelul unei funcţii . Revenirea dintr-o funcţie
Apelul unui subprogram care nu returnează o valoare
(procedură) are forma generală:
nume_funcţie (lista parametrilor actuali);
parametru efectiv = parametru actual = parametru real = parametru
de apel
lista parametrilor actuali = fie
vidă, fie o expresie sau mai multe despărţite prin virgulă
O funcţie care returnează o valoare poate
fi apelată fie printr-o instrucţiune de apel simplă (cazul funcţiilor care nu
returnează valori) şi în plus poate fi apelată ca operand al unei expresii. În
cazul în care funcţia se apelază print-o instrucţiune de apel simplă,
rezultatul funcţiei se pierde. Când funcţia se apelează ca operand, valoarea returnată
va fi utilizată în expresie.
La apelul unei funcţii, valorile parametrilor efectivi se atribuie
parametrilor formali corespunzători. În cazul în care unul din tipul unui
paramatru efectiv diferă de tipul parametrului formal corespunzător, parametrul
efectiv va fi convertit spre parametru formal (dacă este posibil, altfel
compilatorul generează eroare).
În momentul în care se întâlneşte un apel de funcţie, controlul execuţiei programul este transferat primei
instrucţiuni din funcţie, urmând a se executa secvenţial instrucţiunile
funcţiei.
|
Apel funcție
|
Apel procedură
|
|
Z =
nume_funcţie (lista parametrilor actuali);
cout<<(nume_funcţie (lista
parametrilor actuali);
if (nume_funcţie (lista parametrilor
actuali)….)
while (nume_funcţie (lista parametrilor
actuali)….)
|
nume_funcţie (lista parametrilor actuali);
|
STRUCTURA UNUI SUBPROGRAM  Variabilele
dintr-un program C++ pot fi clasificate în:
1.
Variabile globale 2.
Variabile locale 3.
Parametri formali
1. Variabile globale
·
Se
declară în afara oricărei funcţii din program
·
Sunt
alocate static, în segmentul de date al programului
·
Sunt
iniţializate implicit, cu valoarea 0
·
Au
domeniul de vizibilitate tot fişierul sursă, adică pot fi folosite din
locul în care au fost definite şi până la sfârşitul fişierului
·
Au
alocat spaţiu în memorie tot timpul rulării programului
2. Variabile
locale
·
Se
declară doar în interiorul unei funcţii din program,
inclusiv în funcţia main ()
·
Nu
sunt
iniţializate implicit,
dacă nu sunt iniţializate explicit de programator, reţin o valoare oarecare,
numită valoare reziduală
·
Au
domeniul de vizibilitate la nivelul blocului în care au fost declarate,
adică pot fi folosite doar în cadrul acelui bloc de instrucţiuni
·
Au
alocat spaţiu în memorie numai în timpul rulării blocului respectiv de
instrucţiuni
Regula
de omonimie
Ø
În cazul în care există o
variabilă locală care are acelaşi nume cu o variabilă globală, aceste două
variabile se numesc variabile omonime.
Ø Variabilele locale sunt prioritare (ascund) variabilele globale
omonime.
|
int
n=10;
void
f1() { int n=2; cout << n; }
void
main () { f1(); cout << n; }
|
Întrebare.
Cum gestionează compilatorul cele două variabile omonime ?
Răspuns:
Ø
Variabilelor globale li se
rezervă spaţiu de memorare la începutul execuţiei programului, într-o zonă de
memorie numită “zonă de date”. Acest spaţiu va fi ocupat până la încheierea
execuţiei programului.
Ø
Variabilelor locale li se
rezervă spaţiu într-o zonă specială de memorie numită “stiva”. La încheierea
execuţiei subprogramului, conţinutul stivei este eliberat.
Din acest motiv, variabilele globale sun vizibile doar în
interiorul subprogramului în care au fost declarate.
3. Parametri formali –
reprezintă o cale de comunicare între modulul apelant şi funcţia apelată. Pot
fi:
Ø Parametri de intrare – corespund datelor
de intrare din analiza problemei
- Sunt valori transmise de
modulul apelant către funcţia apelată
- Se transmit prin valoare
- Se declară ca orice variabilă
prin tip idvar
Ø Parametri de ieşire (rezultate) –
corespund datelor de ieşire din analiza problemei
-
Sunt valori transmise de funcţia apelată către modulul apelant - Se
transmit prin referinţă, este specificat prin tip& idvar
Parametri
de intrare şi ieşire – sunt parametri formali transmişi prin
adresă, dar care sunt folosiţi şi pentru a transmite date de intrare
Parametrii
formali şi actuali
ü
Parametrii care sunt
declaraţi în antetul unei funcţii se numesc parametri formali,
iar cei care se găsesc în instrucţiunea de apel se numesc parametri efectivi
(actuali sau de apel).
ü
Legătura între parametrii
formali şi cei actuali este dată de regulile următoare:
ü Parametrii actuali trebuie să coincidă ca număr, tip şi
ordine cu parametri formali
ü Transmiterea parametrilor are efectul unei
atribuiri a valorii parametrului actual către parametrul formal corepsunzător
| |
| | ▸ Metode de transmitere a parametrilor unui subprogram | | Metode de transmitere a parametrilor unui subprogram Transmiterea prin
valoare se
foloseşte atunci când funcţia primeşte acea valoare ca o dată de intrare, fără
a transmite în modulul apelant valoarea modificată în subprogram.
Pot fi transmise prin valoare:
a)
valorile reţinute de variabile
b) valoarea unei expresii, care
pot conţine inclusiv apeluri de funcţii; expresiile sunt evaluate înainte de
transfer
Transmiterea prin referinţă se foloseşte
atunci când în urma apelului dorim ca variabila transmisă să reţină valoarea
stabilită în timpul execuţiei subprogramului Exemplu:
|
Exemplul 1
|
Exemplul 2
|
|
# include
<iostream>
using namespace std;
void f1 ()
{
cout << "abc";
}
int main ()
{
f1();
return 0;
}
|
# include
<iostream>
using namespace std;
void f1 (int k)
{
for (int i=1; i<=k ; i++)
cout <<
"abc"<< " ";
}
int main ()
{
f1(3);
return 0;}
|
|
Se va
afisa:
Abc
|
Se va
afişa:
abc abc abc
|
|
Funcţia nu returnează o
valoare
Funcţia nu are
parametri
Apelul funcţiei este o
instrucţiune de apel simplă
|
Funcţia nu returnează o
valoare
Funcţia are un
parametru formal
de tip int
Apelul funcţiei este o
instrucţiune de apel sinplă şi se face cu ajutorul unui parametru actual care
este de acelaşi tip cu tipul parametrului formal corespunzător
|
|
Exemplul 3.3
|
Exemplul 3.4
|
|
# include
<iostream>
# include
<math.h>
using namespace
std;
int prim (int x)
{
int nr_div=0;
for (int i=2; i<=x;
i++)
if (x%i==0)
nr_div++;
if (nr_div==0)
return 1;
else
return 0;
}
int main ()
{
int N;
cout << "N=";
cin >> N;
if (prim(N))
cout << "PRIM";
else
cout << "NU E
PRIM";
return 0;
}
|
# include
<iostream>
# include
<math.h>
using namespace
std;
int prim (int x)
{
for (int i=2; i<=x;
i++)
if (x%i==0)
return 0;
return 1;
}
int main ()
{
int N;
cout << "N=";
cin >> N;
if (prim(N))
cout << "PRIM";
else
cout << "NU E
PRIM";
return 0;
}
|
|
Funcţia returnează
o valoare de
tip int
Funcţia are un
parametru de tip
int
Rezultatul funcţiei
este este
utilizat în cadrul unei expresii.
|
În cazul în care se
întâlneşte
un divizor a lui x se execută instrucţiunea return 0. Astfel apelul funcţiei
se încheie. Dacă x este număr prim, instrucţiunea return 0 nu se execută
niciodată şi în acest caz, după terminarea execuţiei instrucţiunii for, se
execută instrucţiunea return 1 (care determină încheierea execuţiei
funcţiei).
|
!!! Tablourile(sirurile) sunt transmire implicit prin referinta. Asta insemna ca ele isi vor
pastra valorile pe care le vor primi in subprogram. | |
| | ▸ SUBPROGRAME RECURSIVE | | SUBPROGRAME RECURSIVE|
Ce este recursivitatea ?
Spunem despre un subprogram că este recursiv dacă conține în definirea sa un apel la el însuși.
Astfel putem avea două tipuri de recursivitate:
- Directă (atunci când subprogramul conține un apel la el însuși)
- Indirectă (atunci când subprogramul P apelează un subprogram Q care la rândul să conține în
definirea sa un
apel la subprogramul P).
|
Structura unei funcţii recursive
tip nume_funcţie (lista de parameri) {
.................
nume_funcţie (lista de parametri);
//funcţia conține un apel la ea însăși
..................
}
|
Structura unei funcţii recursive indirect apelate prin
intermediul unei alte funcţii:
tip B(lista de parameri) {
.................
A(lista de parametri); //funcţia B apelează funcţia A ..................
}
tip A(lista de parameri) //funcţia A este recursivă şi apelează funcţia B
{.................
if(condiţie
de
continuare)
.................
B(lista de
parametri);
.................. } |
Majoritatea algoritmilor repetitivi se pot implementa atât în
varianta nerecursivă,
folosind cicluri, cât și în varianta recursivă.
Varianta recursivă este recomandată în special pentru problemele definite prin relații de recurentă, care permit o formulare a rezultatelor mult mai
clară și mai
concisă.
Un subprogram recursiv se caracterizează prin proprietatea că se auto-
apelează,
adică din interiorul lui se apelează pe el însuși. Din afara subprogramului facem un prim apel al acestuia, după care
subprogranul se auto-apelează de un anumit număr de ori: la fiecare nouă auto-apelare a subprogramului, se execută din nou
secvența de
instrucțiuni ce reprezintă corpul său, eventual cu alte date, creându-se un așa-numit „lanț de auto-apeluri recursive”.
Putem spune că un subprogram recursiv are același efect ca și un ciclu: repetă execuția unei
anumite
secvențe de instrucțiuni. Dar, la fel ca în cazul unui ciclu, este necesar ca repetarea să nu aibă loc la infinit. De aceea în corpul subprogramului
trebuie să
existe cel puțin o testare a unei condiții de oprire, la îndeplinirea căreia se întrerupe lanțul de auto-apeluri.
|
int f(int n)
{
if (n==0) return 1;
else return n*f(n-1);
}
int main()
{ int n;
cout<<“n=“; cin>>n ;
cout << n <<“! = “<<f(n));
} | | Funcţia factorial este scrisă după definiţia recursivă,
respectiv
varianta iterativă:
|
| |
|
int f (int n)
{ int i,P=1;
for (i=1; i<= n; i++) P=P*i;
return P;
} | |
| |
| |
|
int n ;
// câte numere tipărim
void p(int i)
// procedura p cu parametrul i
{
if (i==n) cout<<n ; // rezolvarea directă (condiţia de STOP)
else {
cout<<i<<; //
Subproblema p(i): tipărim i
p(i+1);
; //
trecem la subproblema p(i+1)
}
}
int main()
{ cout<<“n=“; cin>>n; // citim valoarea lui n
p(1); // apelul iniţial
} | | Cum
scriem un
subprogram recursiv ?
1. Trebuie să formulăm problema în
termeni
recursivi
-
stabilim
formula de recurenţă
-
identificăm
soluţia în cazul rezolvării directe, dată de obicei sub forma condiţiilor iniţiale
- formulăm subproblemele de rezolvat în
cazul în care
nu dispunem de o
formulă de recurenţă
- Scriem subprogramul recursiv:
- soluţia
directă se
scrie sub forma condiţiei de oprire
-
apelul recursiv
rezultă din formula de recurenţă
- la fiecare apel problema parţială trebuie rezolvată
complet | |
| | ▸ Metoda Divide et Impera | | Metoda Divide et ImperaMetoda Divide et Impera (Împarte si Stăpânește) este o metoda de
programare care se aplica problemelor care pot fi descompuse in subprobleme
independente, similare problemei inițiale, de dimensiuni mai mici si care pot
fi rezolvate foarte ușor. Procesul se reia pana când (in urma descompunerilor repetate)
se
ajunge la probleme care admit rezolvare imediata.
Metoda presupune:
- Descompunerea problemei Pb curente
in subprobleme independente SubPbi.
- In cazul in care subproblemele SubPbi. admit
o rezolvare imediata se compun solutiile si se rezolva problema Pb
- Altfel se descompun in mod
similar si subproblemele SubPbi
Evident,
nu toate problemele pot fi rezolvate prin utilizarea acestei tehnici.
Majoritatea algoritmilor de Divide et Impera presupun prelucrări pe tablouri
(dar nu obligatoriu).
Aceasta
metoda (tehnica) se poate implementa atât iterativ dar si recursiv. Dat fiind
ca problemele se împart în subprobleme in mod recursiv, de obicei împărțirea se realizează pana
când șirul
obținut este de lungime 1, caz in care rezolvarea subproblemei este foarte ușoară,
chiar banala.
Spre
exemplu fie un vector X=[x1, x2, x3, …xi … xp… xj, …xn] asupra
căruia se aplica o prelucrare. Pentru orice secvența din vector delimitata de indecșii i si j, i<j exista o valoare p
astfel încât prin prelucrarea secvențelor :
xi, xi+1, xi+2,
xi+3, …xp si xp+1, xp+2, xp+3,
…xj
se
obțin soluțiile corespunzătoare celor doua subșiruri care prin compunere conduc
la obținerea soluției prelucrării secvenței:
xi, xi+1, xi+2,
xi+3, …xj
Aplicație:
Ne
propunem sa determinăm suma elementelor unui vector de întregi utilizând metoda Divide et Impera:
|
2
|
3
|
4
|
1
|
5
|
6
|
8
|
9
|
1
|
10
|
3
|
4
|
4
|
5
|
2
|
6
|
Se
împarte vectorul in doi vectori:
|
2
|
3
|
4
|
1
|
5
|
6
|
8
|
9
|
|
1
|
10
|
3
|
4
|
4
|
5
|
2
|
6
|
Fiecare
dintre cei doi vectori se poate împarți in continuare in alți doi vectori:
|
2
|
3
|
4
|
1
|
|
5
|
6
|
8
|
9
|
|
1
|
10
|
3
|
4
|
|
4
|
5
|
2
|
6
|
La
fel se procedează in continuare:
|
2
|
3
|
|
4
|
1
|
|
5
|
6
|
|
8
|
9
|
|
1
|
10
|
|
3
|
4
|
|
4
|
5
|
|
2
|
6
|
Apoi:
|
2
|
|
3
|
|
4
|
|
1
|
|
5
|
|
6
|
|
8
|
|
9
|
|
1
|
|
10
|
|
3
|
|
4
|
|
4
|
|
5
|
|
2
|
|
6
|
Dat
fiind ca s-au obținut secvențe de vector de lungime 1, nu se mai realizează
descompunerea.
Se
compun soluțiile subsecventelor si se determina soluțiile corespunzătoare:
|
2
|
+
|
3
|
|
4
|
+
|
1
|
|
5
|
+
|
6
|
|
8
|
+
|
9
|
|
1
|
+
|
10
|
|
3
|
+
|
4
|
|
4
|
+
|
5
|
|
2
|
+
|
6
|
Si
in continuare:
|
5
|
+
|
5
|
|
11
|
+
|
17
|
|
11
|
+
|
7
|
|
9
|
+
|
8
|
Apoi:
La
fel:
La
sfârșit:
Iată
o soluție de implementare:
#include<iostream>
using
namespace std;
int
v[20],n;
int divide(int v[20], int li, int ls) // functia primeste ca
parametric extremitatile unei secvente din vector
{int mij, d1 ,d2; //mijlocul, d1 si d2
retin sumele pe extr. Stanga respectiv dreapta
if(li != ls) //algoritmul se
autoapeleaza daca secventele au lungime mai mare de 1
{mij=(li+ls)/2;
d1=divide(v, li, mij);
d2=divide(v, mij+1, ls);
return d1+d2;
}
else
return v[li];
}
int
main()
{
cout<<"n=";
cin>>n;
for(int
i=1;i<=n;i++)
{cout<<"v["<<i<<"]=";
cin>>v[i];}
cout<<"suma
celor "<<n<<" elemente ale vectorului
"<<divide(v, 1, n);
return
0;
}
Se
citește un vector cu n componente numere întregi (numerele se presupun ordonate
crescător) și o valoare întreagă ("nr"). Să se decidă dacă nr se
găsește sau nu printre numerele citite, iar în caz afirmativ să se tipărească
indicele componentei care conține această valoare. Algoritm:
- Funcția care va fi implementată
va decide dacă valoarea căutată se găsește printre numerele aflate pe poziții
de indice cuprins între i și j (inițial, i=1, j=n). Pentru aceasta, se va
proceda astfel:
ü dacă mai
sunt elemente de analizat (adică i<=j, deci nu au fost verificate toate
pozițiile necesare), problema se descompune astfel:
ü dacă nr
coincide cu valoarea de la mijloc, aflată pe poziția de indice (i+j)/2, se treturnează
indicele și se revine din apel (problema a fost rezolvată).
ü în caz
contrar, dacă nr este mai mic decât valoarea testată (din mijloc), înseamnă că
nu se poate afla pe pozițiile din partea dreaptă, întrucât acestea sunt cel
puțin mai mari decât valoarea testată. Nr se poate găsi doar printre
componentele cu indice între i și (i+j)/2 - 1, caz în care se reapelează
funcția cu acești parametri;
ü dacă nr
este mai mare decât valoarea testată (din mijloc), înseamnă că nu se poate afla
în stânga; se poate găsi doar printre componentele cu indicele între (i+j)/2 +
1 și j, caz în care se reapelează funcția cu acești parametri.
ü dacă nu
mai sunt alte elemente de analizat (pentru că i>j se concluzionează că nr nu
apare în cadrul vectorului.
Această problemă nu mai necesită analiza tuturor
subproblemelor în care se descompune, ea se reduce la o singură subproblemă,
iar partea de combinare a soluțiilor dispare. În linii mari, această rezolvare
este tot de tip "divide et impera". #include <iostream>
using
namespace std;
int v[100],
n, nr;
int caut(int v[100], int i, int j) {
if (i<=j)
{
int m = (i+j)/2;
if (nr==v[m]) return m;
else
if (nr<v[m]) return caut(v, i, m-1);
else return
caut(v, m+1, j); }
else return
0;
}
int main( ) {
cout<<”n=”; cin>>n;
for (int i=1; i<=n; i++)
{cout<<”v[“<<i<<”]=”;
cin>>v[i]; }
cout<<”nr=”; cin>>nr;
if (caut (v, 1,n))
cout<< caut (v, 1,n);
else
cout<<” nu s-a gasit ”;
return 0;
}
Probleme propuse:
- Sa se determine produsul a n
numere întregi
- Sa se determine maximul
(minimul) a n numere întregi
- Sa se determine cel mai mare
divizor comun a n valori dintr-un vector
- Sa se caute o valoare intr-un
vector. Daca se găsește se va afișa poziția pe care s-a găsit, altfel
se va afișa un mesaj.
- Sa se caute o valoare intr-un
vector ordonat crescător
- Sa se numere cate valori sunt
egale cu x dintr-un sir de numere întregi citite.
| |
| | ▸ METODA BACKTRACKING | | METODA BACKTRACKINGAceasta tehnica se foloseste
in general la rezolvarea problemelor care indeplinesc urmatoarele conditii:
Ø Solutia lor poate fi pusa sub
forma unui vector S= x1, x2, …, xn cu x1 apartine lui A1, x2 apartine lui A2 …
Ø Multimile A1, A2, …, A
n sunt multimi finite, iar elementele lor se
considera intr-o relatie de ordine bine stabilita.
Ø Nu se dispune de o alta metoda
de rezolvare, mai rapida.
Obs: In multe din probleme multimile A1, A2, …, An
coincid.
La intalnirea unei astfel de probleme, daca nu
cunoastem aceasta tehnica, suntem tentati sa generam toate elementele
produsului cartezian A1* A2* …* An si fiecare
element sa fie testat daca este solutie.
Ex. Consideram generarea
permutarilor multimii {1, 2, 3, …, n} unde n este un
numar natural.
In cazul de fata A1
=A2 =… = An = {1, 2, 3, …, n} = A
(notatie). Trebuie determinata o multime x1, x2, …, x
n cu propietatea ca x1
, x2, …, xn apartin lui A.
Elementul 1 * 1 * … * 1 este un element al produsului
cartezian A * A *… * A dar nu este o permutare a
multimii A fiind ca nu respecta
propietatea unei pertutari si anume ca toate elementele sunt distincte intre
ele. Deci daca s-a ales un element i care
apartine lui A atunci celalat element va
trebui sa fie diferit de i.
Elementele vectorului solutiei
se vor completa pe rand. Astfel x2 va primi o valoare doar dupa ce x1
a primit o valoare si va trebui sa fie
diferita de aceasta.
In general xk+1 va primi o valoare daca xk
a primit o valoare si daca x1
<>
x2 <> … <>xk <> xk+1
x1 va primi valoarea primului element al multimii
A. Se vor verifica conditiile
de continuare adica in sirul x al
solutiilor sa nu fie doua elemente egale, dar fiind ca sirul contine un singur
element acestea sunt indeplinite. x2 va primi la randul sau valoarea primului
element din A numai daca sunt indeplinite conditiile
de continuare. Deoarece atat x1 are deja valoarea primului element al multimii
A aceste conditii nu sunt indeplinite si deci va trebui
sa se aleaga o alta valoare pentru x2 si anume urmatorul element din A.
Daca xk
a primit o valoare atunci xk+1 va primi primul element din A daca
sunt indeplinite conditiile de continuare.
Daca k = n si sunt
indeplinite conditiile de continuare atunci
s-a determinat o solutie si se va afisa solutia
Daca primul element din A se afla
deja printre elementele x1, x2, …, xk
atunci se va alege urmatorul
element din A.
Daca in A nu se
mai afla nici un element care sa se aleaga si sa respecte conditiile
de continuare atunci se revine la xk
si se alege urmatorul
element din A de dupa elementul xk
Algoritmul
Backtraking este:
K=1
X1= 1
Cat timp k>0 executa
cat timp k <
n si sunt indeplinite Conditiile de
continuare executa
k =
k+1
xk = 1
Sf. Cat timp
Daca k=n si sunt indeplinite
Conditiile de continuare atunci
Tipareste Solutia – vectorul X
Sf Daca
Cat timp Nu mai sunt Elemente in A de ales executa
k = k –1
Sf Cat timp
Daca k >0 atunci
x
k = xk + 1
Sf Daca
Sf Cat timp
| |
| | ▸ Teoria Grafurilor | | Teoria GrafurilorTeoria
Grafurilor.
Notiuni
introductive.
Def. Se considera multimile finite X = {
x1, x2,
…, xn} si multimea U, care este produsul cartezian al multimii X cu
ea insasi.
Se numeste graf o
pereche ordonata de multimi (X, U), X fiind o multime finita si nevida de
elemente numite varfuri sau noduri, iar U o multime de perechi (submultimi cu
cate doua elemete) din X, numite muchii
sau arce.
Multimea X se numeste multimea
nodurilor sau varfurilorr, iar multimea U se numeste multimea muchiilor sau
arcelor.
Un graf va fi notat G = (X, U),
iar in figurarea sa nodurile se vor desena prin numere sau litere, iar muchiile
prin linii neorientate si arcele prin linii orientate.
Def. Se spune ca multimea U are propietatea de simetrie daca si numai daca
avand [xk, xi] in U rezulta si [xi, xk] tot in U.
Def. Daca multimea U are propietatea de simetrie se spune ca graful este un
graf neorientat.
Def. Daca multimea U nu are propietatea de
simetrie se spune ca graful este un graf orientat sau directionat sau digraf.
Pentru un arc (xi,
xj), xi este numit baza arcului sau originea sau
extremitatea initiala iar xj este numit varful grafului sau extremitatea finala
sau terminala. Se mai spune ca xi si xj sunt adiacente. Astfel arcul
(xi, xj) este incident spre exterior cu xi si incident spre interior cu xj.
Daca un varf nu
este nici extremitate initiala si nici extremitate finala pentru nici un arc
atunci el este varf izolat.
Def. Se considera graful G= (X, U). Daca
multimea U este vida atunci graful se numeste nul si reprezentarea lui
se reduce la figurarea unor puncte izolate.
Def. Se numeste gradul unui varf x al
unui graf numarul de muchii incidente cu x si se noteaza cu d(x).
Daca un varf are
gradul 0 atunci el este varf izolat iar daca are gradul 1 atunci el este varf terminal.
Conventie:
Fie un graf G = (X, U). Atunci
unde n este numarul de varfuri iar m este numarul de muchii al grafului.
Corolar. Fiecare graf are un numar
par de varfuri cu grad
impar.
Def. Fie graful G=(X, U) si V U. Graful Gp=
(X, V) se numeste graf partial al grafului G.
Numărul de grafuri parţiale ale lui G este 2m.
Soluţie: Numerotăm muchiile grafului de la 1 la m. Fiecărui
graf parţial îi putem asocia în mod biunivoc o funcţie f:{1, 2, 3, …, m} à
{0, 1} astfel: dacă muchia numerotată i
aparţine grafului parţial va avea valoarea 1 și 0 dacă nu aparține.
Numărul de grafuri parţiale este egal cu numărul de funcţii
definite, adică 2m (considerăm că un graf este parţial al său).
Def. Fie graful G=(X, U). se numeste graf complementar
al grafului G, graful Gc=(X, U’) cu prop. ca doua varfuri sunt adiacente in
Gc daca ele nu sunt adiacente in G.
Def. Fie graful G=(X, U) si Y inclusa in X. Fie Vinclusa in U, unde
V
contine toate muchiile din U care au extremitatile in multimea Y. Graful Gs=(Y,
V) se numeste graf subgraf al
grafului G.
Def. Se considera U = X x X – D. Atunci graful
G=(X, U) se numeste graf complet si se noteaza Kn (n fiind numarul
de varfuri al grafului). Si D = { x x
| x apartine lui X }
Prop. Kn este graf neorintat cu n
varfuri are n(n-1)/2 muchii.
Def. Graful G se numeste bipartit daca
exista doua multimi nevide A si B astfel incat X = A U B si A Ç B =
Æ si
orice
muchie u a lui U are o extremitate in A si cealalta in B.
Def. Graful G bipartit se numeste bipartit
complet daca intre orice varf xi
din A si orice varf xk din B
exista muchia [xi, xk].
Metode de
reprezentare
Reprezentarea
geometrica.
Fie graful G =
(X, U) unde X = {1, 2, 3, 4, 5, 6}
U = {[1, 2]; [2, 3]; [1, 4], [4, 5];
[2, 6]}
Reprezentarea varfurilor
se va face printr-un cerculet in interiorul caruia se va trece numarul
corespunzator varfului sau o litera . | |
| | ❑ MEMORAREA UNUI GRAF | | MEMORAREA UNUI GRAF 1.
Matricea de adiacenta. Fie un graf G =
(X, U), X = {x1, x2, …, xn}. Asociem lui 1 pe
x1, 2 pe x2, … Astfel
reprezentarea grafului va fi o matrice patratica de dimensiune n. A[i][j] primeste
valoarea 1 daca I si j sunt adiacente
0 in caz contrar Ex. Pentru graful de
mai sus: G = (X, U) unde X = {1, 2,
3, 4, 5, 6}
U = {[1, 2]; [2, 3]; [1, 4], [4, 5]; [2, 6]}

2.
Lista
de adiacenta Pentru fiecare nod din graf se pastreaza cate o lista care
contine nodurile adiacente cu acesta. Ex: Pentru graful de mai sus 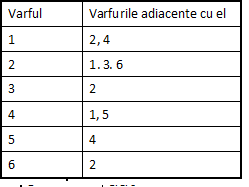
Metoda constă în crearea / memorarea a doi vectori alfa şi beta definiţi astfel: alfa[1] = 1 alfa[i] = 1 + suma gradelor nodurilor 1, 2, 3, ..., i-
1 sau
alfa [i]
= alfa [i-1] + grad (i) alfa = (1, 3, 6, 7, 9, 10, 11) beta reprezintă înşiruirea
nodurilor din coloana din dreapta a tabelului alăturat. beta = (2, 4, 1, 3, 6, 2, 1, 5, 4, 2)
3.
Matricea
costurilor Fiecarui muchie i se
va atribui un numar Real mai mare ca 0, reperezentand costul muchiei respective c : U --> R+ Astfel c este o matrice patratica de dimensiune n
definita astfel: C[i][j] primeste
valoarea v
daca i si j sunt adiacente, iar v reprezinta costul muchiei
;
0 in caz contrar 4.
Matricea de incidenta Se noteaza muchiile grafului cu m1, m2,
…, mm. Metoda consta in alcatuirea unei matrici B cu n linii si
m coloane (n- nr. de varfuri si m – nr. de muchii) B[i][j] primeste
valoarea 1 daca daca nodul I este incident cu muchia mj.
0 in rest 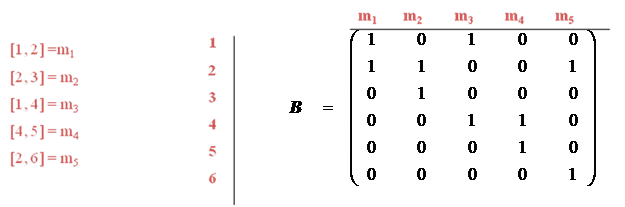
5. Cu ajutorul a doua siruri
Se vor construi doua siruri X si Y astfel
incat muchia mi are prima extremitate in sirul xi
iar a doua in sirul yi 
| |
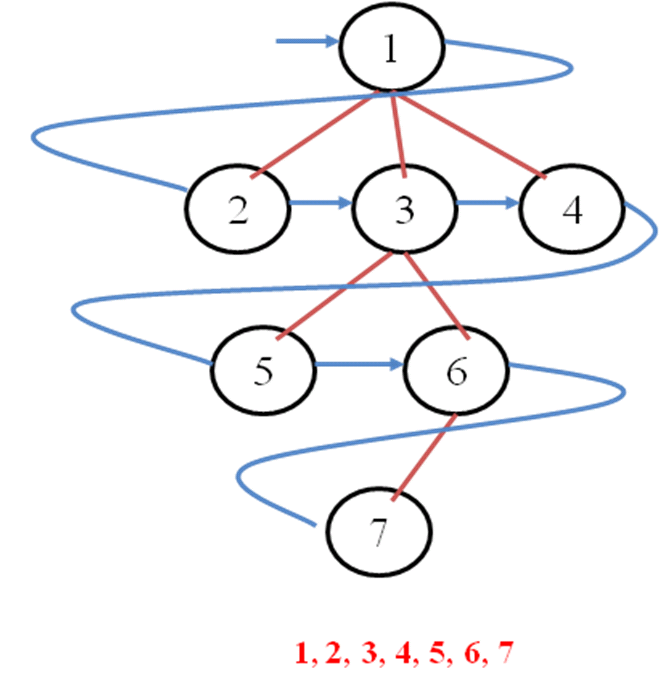
| | ❑ Parcurgerea grafurilor in latime (Breadth First) | | Parcurgerea grafurilor in latime (Breadth First)Derularaea algoritmului
presupune alegerea la un moment dat,
dintre vecinii unui varf, pe acela ce nu a fost vizitat inca. Acest lucru este
posibil prin folosirea unui vector VIZITAT de dimensiune n ale
carui componente se definesc astfel:
Vizitat[i] = 1 daca nodul I a fost vizitat
= 0 in rest
Se va folosi o structura de tip coada.
Algoritmul parcurgerii in latime
Pas. 1. Se prelucreaza
varful initial k
Pas.
1.1. Se adauga varful k in
coada
Pas.
1.2. Varful k se considera vizitat
Pas. 2. Cat
timp coada este nevida se executa:
Pas.
2.1. Pentru toti vecinii j nevizitati inca ai varfului k
Pas. 2.1.1. Se adauga varful j in coada
Pas.
2.1.2. Varful j se considera vizitat
Pas.
2.2. Se reia de la Pas. 2.1. (varful j devine varful k)
void Parc_Lat()
{
prim = 1;
ultim = 1;
Cd[1] = 1;
cout<<endl<<Cd[1];
Viz[1] = 1;
while (prim<=ultim)
{
nod =
Scoate(Cd, prim);
for (j=1
; j<= n; j++)
if ((a[nod][j] == 1) && (Viz[j] ==
0))
{
Add(Cd, ultim, j);
cout<<" "<<j;
Viz[j]=1;
}
}
} Cd – coada Viz – vectorul
VIZITAT Scoate – functie care
returneaza primul element din coada Add – adauga
un element in
coada Prim – indicele primului
element din coada (la scoatere creste cu o unitate) Ultim – indicele ultimului
element din coada (la adaugare creste cu o unitate) In coada vor fi elemente
atata timp cat
&a
mp;nb
sp;
prim <=ultim
 | |
| | ❑ Parcurgerea grafurilor in adancime (Depth First) | | Parcurgerea grafurilor in adancime (Depth First)Derularaea algoritmului
presupune vizitarea unui varf apoi a
varfului adiacent cu acesta si asa mai departe , pana se revine la un alt varf
si se alege un alt varf nevizitat inca.
Acest lucru este posibil prin folosirea unui vector VIZITAT de
dimensiune n ale
carui componente se definesc astfel:
Se va folosi o structura de tip stiva.
Algoritmul parcurgerii in adancime
Pas. 1. Se
adauga varful k in stiva si se
considera vizitat
Pas. 2. Se
analizeaza varful k
Pas. 2.1. Se
cauta primul din vecinii nevizitati
Pas.
2.1.1. Daca exista (fie j acesta) se
dauga in stiva si se considera vizitat
Pas.
2.1.2. Daca nu exista se scoate urmatorul nod din stiva (fie j acesta)
Pas.
2.2. Varful j devine varful ce trebuie analizat (varful k)
Pas. 3. Cat timp stiva este nevida se executa Pas.
2.
void Parc_Ad() {
ultim = 1;
St[1] = 1;
cout<<endl<<St[1];
Viz[1] = 1;
while (ultim>0) {
nod = Scoate(St, ultim);
j=0;
ok=0;
for (j=1; ((j<=n)
&& (ok==0)); j++)
if((a[nod][j] == 1) && (Viz[j] ==
0)) {
Add(St, ultim, j);
cout<<" "<<j;
Viz[j]=1;
ok=1;
}
while ((ok==0) &&
(j<=n));
if (ok==0) ultim--;
}
}
St – stiva
Viz – vectorul VIZITAT
Scoate – functie care
returneaza primul element din stiva
Add – adauga un element in
stiva
Ultim – indicele ultimului
element din stiva (la adaugare creste cu o unitate)
Ok – indica daca a fost
gasit un alt varf adiacent cu cel prelucrat. ( daca e 1 inseamna ca s-a
gasit)
In stiva vor fi elemente
atata timp cat ultim > 0 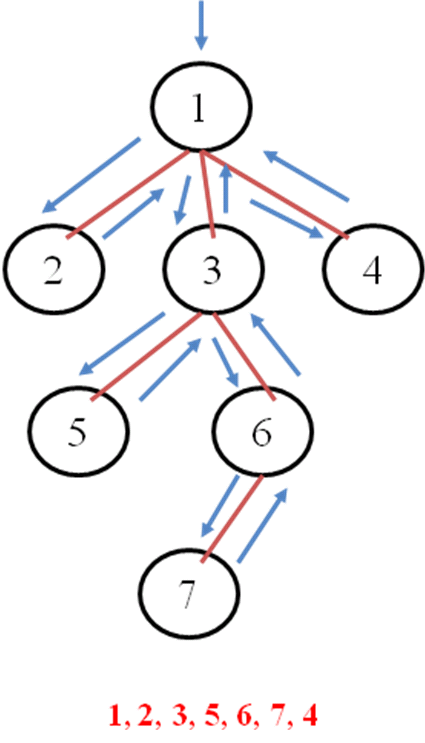
| |
| | ❑ CONEXITATE IN GRAFURI | | CONEXITATE IN GRAFURIDef:
Fie graful G=(X, U). Numim lant o succesiune de varfuri L = {x1,
x2, …,
xp} cu
propietatea ca oricare doua varfuri
succesive sunt adiacente, adica [x1, x2] Î U,
[x2, x
3] Î
U, …, [xp-1,
xp]
Î
U. Varfurile x1 si xp se
numesc extremitatile lantului, iar
numarul de muchii ce il compun se numeste lungimea lantului. Def:
Daca varfurile x1, x2,
…, xp sunt distincte doua cate doua, lantul se numeste lant elementar. In caz
contrar lantul se numeste neelementar. Def: Daca intr-un lant, toate muchiile
sunt
diferite intre ele, lantul se numeste simplu, in caz contrar lantul se
numeste compus. Def:
Daca varfurile x1 si xp coincid lantul se numeste
ciclu. Daca un ciclu are o lungime para, el se numeste par, altfel
impar Def: Daca intr-un ciclu, toate varfurile sunt
distincte intre ele, cu exceptia primului si ultimului atunci ciclul se numeste
ciclu elementar. Def: Un graf se numeste conex daca
oricare ar fi doua varfuri x si y, exista un lant ce le leaga. Def:
Fie graful G=(X, U). Un subgraf C = (X1,
U1) al sau conex se numeste componenta conexa a grafului G
daca are in plus propietatea ca nu exista nici un lant in G sa lege un varf din
X1 cu un nod din X – X1. Teorema:
Componentele conexe Xi ale
unui graf genereaza o partitie a lui X, adica multimile Xi au
propietatile: 1. Xi
¹ Æ, pentru orice i Î N 2. Xi
¹ Xj Þ Xi Ç Xj = Æ , pentru orice i Î N 3. reuniunea lor este chiar X Teorema:
Un graf este conex numai si numai daca are o singura componenta conexa.
Def:
Fie graful G=(X, U). Daca exista varfuri intre care exista mai mult de o
muchie, graful este numit multigraf. Def: Fie graful G=(X, U).
Daca exista un lant
elementar care contine toate varfurile grafului, lantul se numeste lant
hamiltonian. Def:
Daca intr-un lant hamiltonian varful initial si varful final coincid
lantul se numeste ciclu hamiltonian iar despre graf spunem ca se numeste graf
hamiltonian Teorema:
Kn (graful complet) este un graf hamiltonian Def: Fie graful G=(X, U).
Daca exista un lant
care contine toate muchiile grafului o singura data fiecare, lantul se numeste lant
eulerian. Def:
Daca intr-un lant eulerian varful initial si varful final coincid lantul
se numeste ciclu eulerian iar despre graf spunem ca se numeste graf eulerian
Teorema: Un
graf G fara varfuri izolate este eulerian daca si numai daca este conex si
gradul fiecarui varf este par. | |
| | ❑ Determinarea numarului de componente conexe ale unui graf | | Determinarea numarului de componente conexe ale unui grafSe da un graf
G=(X, U). Sa se determine numarul de
componente conexe ale grafului.
Graful se va citi c o succesiune de muchii (doua varfuri).
Numarul de muchii este m.
Odata cu citirea unei muchii se stabileste apartenenta celor
doua varfuri la o componenta conexa. Astfel avem 3 cazuri:
- Daca
varfurile nu apartin de nici o componenta conexa atunci se va crea una
noua care sa contina cele doua varfuri
- Daca
unul din varfuri apartine de o componenta conexa atunci se va introduce si
celalalt sau ambele varfuri apartin de o componenta conexa, atunci nu se
va face nimic.
- Daca
unul din varfuri apartine la o componenta conexa si celalalt la o alta
componenta conexa atunci cele doua componente conexe se vor uni si va
contine toate varfurile de la cele doua si numarul de componente conexe va
scade cu 1.
Algoritmul de determinare a nr. de componente conexe.
Pentru I = 1 la m executa
Citeste x[I], y[I];
k=0;
Pentru j = 1 la nc executa
Daca ((x[I] apartine CompCon[j]) sau (y[I] apartine
CompCon[j])) atunci
k = k+1;
u[k] = j;
SfDaca
SfPentru
Daca (k =0) atunci
nc = nc + 1;
CompCon[nc] = {x[I], y[I]}
Altfel
Daca (k=1) atunci
CompCon[u[1]] = CompCon[u[1]] U {x[I],
y[I]}
&a
mp;nb
sp; Altfel
CompCon[u[1]] = CompCon[u[1]] U CompCon[u[2]];
nc =
nc –1;
SfDaca
SfDaca
SfPentru
m – numarul de muchii
x[I] – sir ce contine prima extremitate a muchiei
y[I] - sir ce contine a doua extremitate a muchiei
nc – numarul de componente conexe
CompCon[j] – vector ce memoreaza varfurice ce fac parte
din componenta conexa j.
u[k] – memoreaza numarul componentei conexe din care fac
parte cele doua varfuri
k – ne spune in ce situatie ne aflam (1, 2, sau 3) | |
| |
|